
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 라때는
- 스타링크
- AWS
- 이력서는 PDF로
- 파이어베이스
- Rekognition
- 대기업갑질
- Exception Safety
- 이대남
- 꼬북좌
- RDS
- 익셉션
- #개발
- 대학인생
- 글쓰는법
- react-redux
- Firebase
- GSON
- 스타링크 국내진출
- 언박싱
- 애플워치7
- 안드로이드오토
- 개발자 이력서
- parse
- #대화
- 브레이브걸스
- 스마트워치
- 팜피 주식회사
- 통신3사
- 리액트
- Today
- Total
kwondroid의 개발 세계
HTML로 얼굴인식 BoundingBOX를 그려보기('브'론트) 본문
하던 프로젝트가 엎어져서 심심함을 풀 놀거리를 찾고 있었다.
뭘 할까 고민하던 중 예전에 해볼까 생각만 했던 것이 생각이 났다. 바로 얼굴인식으로 노는 것이었다.
그러나 내 주제에 직접 얼굴인식 머신러닝을 돌리는 건 무리다. 그러나 aws의 rekognition를 이용해 얼굴을 인식시키고 그 결괏값을 프론트에 출력을 하는정도는 할 수 있다. 그래서 코딩을 시작했다.
먼저 rekognition엔 무슨 서비스가 있는지 보면 객체 및 장면 감지, 이미지 조절, 얼굴 분석, 유명 인사 인식, 얼굴 비교, 이미지 내 텍스트, PPE(개인 보호 장비) 감지 가 있다.
이 중에서 이번에 갖고 놀 서비스는 '얼굴 분석' 서비스이다.
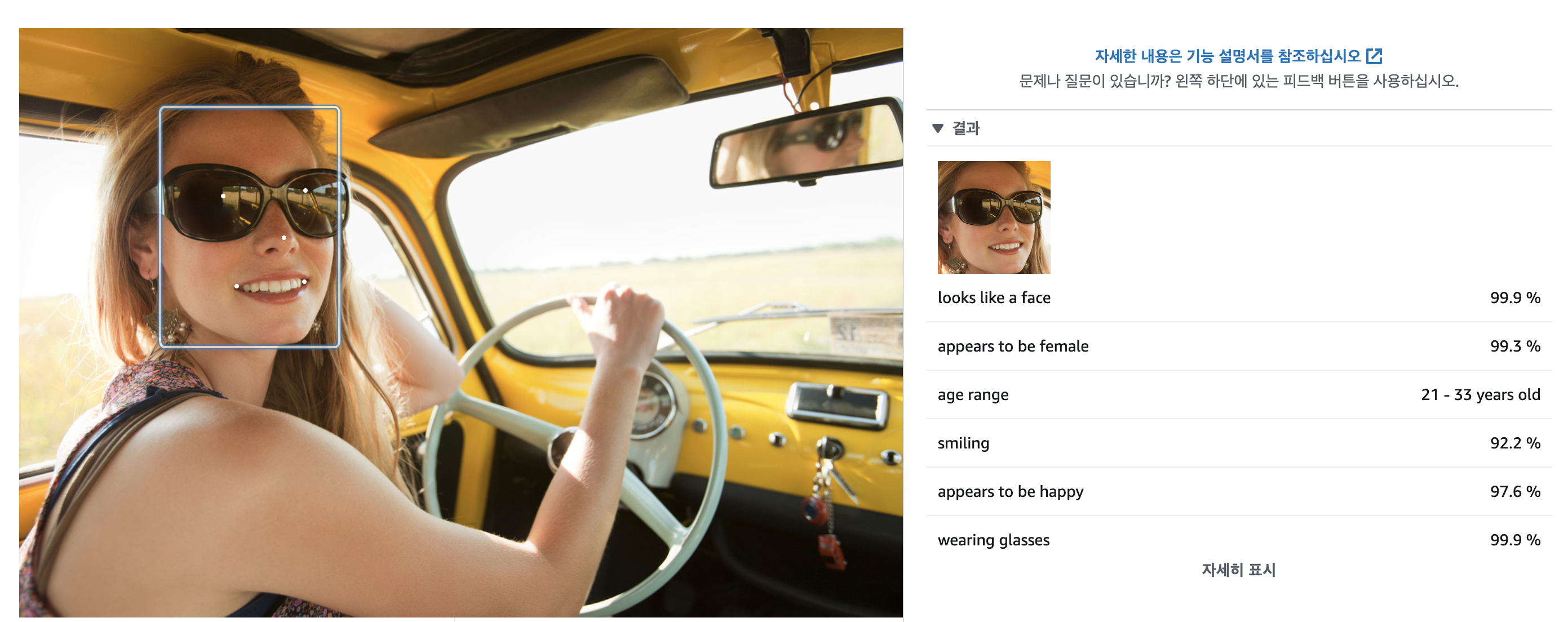
이런 식으로 얼굴의 위치를 파악하고 그 얼굴의 여러 가지 정보를 알 수 있는 서비스다.
이번엔 별다른 거 없이 얼굴(들)의 위치만 파악하고 그 위치를 표시해주는 것만 만들어볼 것이다. (이것도 충분히 복잡하다... ㅠ)
우선 데모부터 해보자
내가 테스트할 이미지는 최근에 입덕 한 브레이브걸스의 릴레이 댄스 썸네일이다.

일단 코딩에 앞서 사랑한다는 말을 먼저 하고자 한다. 꼬북좌로 입덕 해서 단발좌에 치이고 뱃살좌에 난 죽었다...

각설하고 위의 유튜브 영상 썸네일을 AWS에서 제공하는 데모로 분석을 해보면 이런 Response를 받을 수 있다.
사실 훨씬 더 긴데 얼굴 하나당 주는 데이터가 상당히 많아 코드를 다 담을 수 없어서 이렇게 일부만 캡처를 했다.

우선 이 코드는 백앤드에선 쓸데가 없다. 서버 측에서 별도의 DTO를 만들어 관리할 필요 없다. 다 AWS 측에서 만들어 제공을 하고 있을뿐더러 이 데이터를 서버에서 따로 가공하지 않고 그대로 JSend 규격에 맞게 Wrap 하여 프런트 쪽에 그대로 토스만 할 것이기 때문이다.
그러나 프런트 앤드 쪽에선 타입 스크립트를 사용할것이기에 타입 정의를 해줘야한다.
quicktype 통해 타입을 뽑아내면 이런 결과를 얻을 수 있다.

타입스크립트 외에도 여러 가지 언어를 지원하니 나중에 필요할 때 잘 쓰길 바란다.

아무튼 여기서 뽑아낸 타입을 그대로 복사하여 리액트 쪽에 face.d.ts에 그대로 붙여 넣었다.
그다음 이미지 파일을 서버에 업로드하여 얼굴 정보를 받아오는 데까지 먼저 코딩을 할 것이다.
우선 껍데기 먼저 작성했다.
이미지 태그가 있긴 하지만 이 이미지 태그 안엔 합성된 이미지를 적용하지 않을 것이다. 정확히 말하면 이미지 합성 자체를 하지 않을것이다. 오직 div 태그로만 얼굴 위치를 표시할 것이다. 이미지 자체를 합성을 한 이유는 추후 div의 onmouseover과 같은 이벤트로 상호작용을 할 수 있도록 확장의 여지를 남기기 위해서다.
const Parents = Styled.div`
position : relative;
`
const Child = Styled.div`
position : absolute;
background-color :rgba( 255, 255, 255, 0 );
`
<div>
<Parents>
<Child style={{ ...childViewStyle }}>{faceDivList}</Child>
<img ref={imgRef} src={imgAssets} onLoad={() => setLoad(() => false)} />
</Parents>
<input
type="file"
accept="image/png, image/jpeg , image/jpg"
onChange={fileChange}
/>
</div>
그다음 각 뷰에 엮여 있는 여러 가지 변수(함수)는 이렇게 작성했다.
const imgRef = useRef<HTMLImageElement>(null)
const [imgAssets, setImgAssets] = useState<any>()
const [childViewStyle, setChildViewStyle] = useState({})
const [isLoading, setLoad] = useState<boolean>(false)
const [faceDivList, setFaceDivList] = useState<Array<JSX.Element>>()
const imgSizeCheck = useCallback((): ImgSize => {
const preview = imgRef.current
const width = preview?.clientWidth
const height = preview?.clientHeight
return { width, height }
}, [imgRef])
const setImage = useCallback((image: any) => {
const reader = new FileReader()
reader.readAsDataURL(image)
reader.onloadend = () => {
const base64 = reader.result
if (base64) setImgAssets(base64.toString())
}
}, [])
const getFaceInfo = useCallback(async (file: any) => {
const formData = new FormData()
formData.append("file", file)
try {
setLoad(() => true)
const { status, data }: returnType = await callFaceInfo(formData)
if (status === 200 && data.status === success) {
const serverData: Data = data.data
const facesInfo = serverData.faceDetails.map(
(object: any, index: number) => {
const { left, height, top, width } = object.boundingBox
return (
<FaceDiv
key={index}
position="absolute"
left={`${left * 100}%`}
top={`${top * 100}%`}
width={`${width * 100}%`}
height={`${height * 100}%`}
/>
)
}
)
setFaceDivList(facesInfo)
}
} catch (e) {
alert(e)
}
}, [])
const fileChange = useCallback(
async (e: any) => {
setImage(e.target.files[0])
getFaceInfo(e.target.files[0])
},
[setImage, getFaceInfo]
)코드가 길지만 천천히 다뤄보자.
이 코드는 input을 통해 파일이 선택이 되면 이미지를 적용하고 서버에 업로드하고 얼굴 정보를 받아와 각 위치에 그림을 그리는 것까지 연쇄적으로 일어나게 되는 구조이다.
const fileChange = useCallback(
async (e: any) => {
setImage(e.target.files[0])
getFaceInfo(e.target.files[0])
},
[setImage, getFaceInfo]
)setImage 메서드는 그저 단순히 사용자가 선택한 이미지를 img를 띄우는 역할밖에 하지 않는다.
src안에는 단순히 e.target.files[0]을 넣었을 때는 적용이 안되기에 이렇게 base64 이미지로 변환하여 적용하였다.
const setImage = useCallback((image: any) => {
const reader = new FileReader()
reader.readAsDataURL(image)
reader.onloadend = () => {
const base64 = reader.result
if (base64) setImgAssets(base64.toString())
}
}, [])getFaceInfo 함수에선 파일 업로드 작업이 일어난다.
const success = "success"
const getFaceInfo = useCallback(async (file: any) => {
const formData = new FormData()
formData.append("file", file)
try {
setLoad(() => true)
const { status, data }: returnType = await callFaceInfo(formData)
if (status === 200 && data.status === success) {
const serverData: Data = data.data
const facesInfo = serverData.faceDetails.map(
(object: any, index: number) => {
const { left, height, top, width } = object.boundingBox
return (
<FaceDiv
key={index}
position="absolute"
left={`${left * 100}%`}
top={`${top * 100}%`}
width={`${width * 100}%`}
height={`${height * 100}%`}
/>
)
}
)
setFaceDivList(facesInfo)
}
} catch (e) {
alert(e)
}
}, [])formdata 형식으로 이미지를 서버로 업로드하였고 그에 대한 데이터를 받았다.
callFaceInfo 함수는 별거 없다. 그냥 axios요청을 보내는 함수다.
// /src/lib/axiosInstance.ts
import axios, { AxiosInstance } from "axios"
class AxiosInstanceClass {
private static instance: AxiosInstance
// new 클래스 구문 사용 제한을 목적으로
// constructor() 함수 앞에 private 접근 제어자 추가
private constructor() {}
// 오직 getInstance() 스태틱 메서드를 통해서만
// 단 하나의 객체를 생성할 수 있습니다.
public static getInstance(): AxiosInstance {
if (!AxiosInstanceClass.instance) {
AxiosInstanceClass.instance = axios.create({
baseURL: "http://localhost:8080",
timeout: 5000,
})
}
return AxiosInstanceClass.instance
}
}
const axiosInstance: AxiosInstance = AxiosInstanceClass.getInstance()
export const callFaceInfo = (formData: FormData) =>
axiosInstance.post("/test/img", formData)
AxiosInstance 타입 찾는데 고생 좀 했다. 카톡방에서 답변해주신 고수분들께 감사하다는 말을 하고 싶다.
if문 뒤에 else를 별도로 두지 않은 이유는 어차피 axios 모듈에서 Exception이 터지면 알아서 catch문을 실행하게 될 거고 if의 조건도 여러 개로 분기할 필요성을 못 느꼈기에 그냥 이렇게 작성했다.
data라는 변수가 조금 괴랄하게 관계되어 있는데 axios와 JSend 조합의 문제 아닌 문제점 때문이다.
axios가 요청을 하고 return 하는 변수중 status와 data는 각각 http code와 서버에서 던져준 데이터가 담겨있다. 그리고 JSend의 형식도 이렇다.
{
"status" : "success",
"data" : {
"title" : "hello world"
}
}즉 axios의 변수명과 JSend의 변수명이 겹치기 때문에 이렇게 구조 분해 할당도 안되는 것이다.
이런 관계가 된다. ServerData는 아까 위에서 무지 길다고 했던 JSON의 구조의 타입이다.
interface ServerData {
status: String
data: Data
}
interface returnType {
status: number
data: ServerData
}어찌 됐든 구조 분해 할당도 못하고 억울하게 데이터를 받긴 했다.
이다음은 데이터를 이용해서 얼굴 위치에 맞게 div를 만들어주는 동작이다.
const FaceDiv = (locateInfo: any): JSX.Element => {
return <div style={{ border: "3px solid blue", ...locateInfo }} />
}
const facesInfo = serverData.faceDetails.map(
(object: any, index: number) => {
const { left, height, top, width } = object.boundingBox
return (
<FaceDiv
key={index}
position="absolute"
left={`${left * 100}%`}
top={`${top * 100}%`}
width={`${width * 100}%`}
height={`${height * 100}%`}
/>
)
}
)
// /types/face.d.ts
export interface Data {
faceDetails: FaceDetail[]
}
export interface FaceDetail {
boundingBox: BoundingBox
ageRange: AgeRange
smile: Beard
eyeglasses: Beard
sunglasses: Beard
gender: Gender
beard: Beard
mustache: Beard
eyesOpen: Beard
mouthOpen: Beard
emotions: Emotion[]
landmarks: Landmark[]
pose: Pose
quality: Quality
confidence: number
}
export interface BoundingBox {
width: number
height: number
left: number
top: number
}이쯤 돼서 aws 측에선 어떻게 데이터를 던져줘야 하는지 알아야 하는데 aws가 이에 대해 기갈나게 설명을 잘해준다.
https://docs.aws.amazon.com/ko_kr/rekognition/latest/dg/images-displaying-bounding-boxes.html
경계 상자 표시 - Amazon Rekognition
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com

위의 문서와 같이 각 항목의 '비율'을 뱉어주는 것이기에 저렇게 단순히 100만 곱해주면 된다. 당연하게도 이미지의 사이즈가 동적으로 바뀌어야 한다면 그에 따라 계산식이 조금씩 달라질 것이다.
하나 언급해야 할 것이 있는데 FaceDiv의 position이 absolute라는 것이다. html은 위에서 아래로 블록처럼 쌓이는데 이 absolute는 내 마음대로 이리저리 잘 돌아다닐 수 있다. 근데 내가 설명하는 것보다 잘 쓰인 글 하나 보는 게 훨씬 낫기에 링크 하나로 퉁쳐야겠다.
앞에 써놓은 jsx 껍데기에 대한 설명도 동시에 되는 글이다.
CSS position 속성으로 div 위에 div 겹치기
기획전 페이지 퍼블리싱을 해 두었는데 일부 기획전에 마감 처리를 해야 해서 div 위에 div를 겹쳐 올리는 방식으로 기획전 조기 마감을 표현했다. CSS position 속성을 이용하면 손쉽게 div 위에 div를
heinafantasy.com
여기서 잠시 코딩을 멈추고 jsx를 다시 한번 보자
<div>
<Parents>
<Child style={{ ...childViewStyle }}>{faceDivList}</Child>
<img ref={imgRef} src={imgAssets} onLoad={() => setLoad(() => false)} />
</Parents>
<input
type="file"
accept="image/png, image/jpeg , image/jpg"
onChange={fileChange}
/>
</div>아직 childViewStyle, faceDivList, imgRef, imgAssets, setLoad에 대해 설명을 하지 않았다.
FaceDiv가 어디에 위치해야 할지 정보는 받았지만 이 상태에선 제대로 출력을 할 수 없다. 왜냐하면 Child div의 크기가 정상적이지 않기에 그 안의 FaceDiv들이 제대로 위치할 수 없기 때문이다.
이를 제대로 위치시키는 것은 img 태그의 onLoad 이벤트를 시작으로 진행된다.
const [isLoading, setLoad] = useState<boolean>(false)
const [faceDivList, setFaceDivList] = useState<Array<JSX.Element>>()
const imgRef = useRef<HTMLImageElement>(null)
const imgSizeCheck = useCallback((): ImgSize => {
const preview = imgRef.current
const width = preview?.clientWidth
const height = preview?.clientHeight
return { width, height }
}, [imgRef])
useEffect(() => {
if (isLoading) {
setFaceDivList(undefined)
} else {
const { width, height } = imgSizeCheck()
setChildViewStyle({ width, height })
}
}, [isLoading, imgSizeCheck])img태그의 onLoad 이벤트가 발생하여 isLoading의 값이 바뀌게 되면 useEffect의 함수가 실행이 된다.
분기문을 한 이유는 FaceDiv가 화면에 있는 채로 새로운 이미지를 업로드하게 되면 이미지는 바뀌었지만 FacdDiv는 그대로 위치하게 되어 화면에 둥둥 떠다니기 때문이다.
얼굴이 인식이 많이 되어 이미지 처리 시간이 길어지거나 네트워크가 느린 등 반응 속도가 늦어질수록 더욱 도드라지게 되어 이 분기가 있는 것이 좋다고 판단하였다.
이 분기로 사진 변경과 동시에 FaceDiv가 동시에 바뀌지는 않지만 사진 속 FaceDiv가 둥둥 떠다니다 갑자기 바뀌는 것보다는 훨씬 보기 좋은 동작이라고 느꼈기에...
useState의 세터(setter)는 '이 상황에서는' 이렇게 안 해도 무방하다. 사실 다른 작업을 하려고 했었는데 그냥 안 했고 세터는 굳이 안 건들여도 로직에 문제가 없기에 손을 안 댄 것뿐이다.
[react] useState의 비동기적 속성, 함수형 업데이트
useState의 비동기적 속성, 함수형 업데이트에 대해서 알아보기
velog.io
또한 분기문을 넣은 또 다른 이유는 img태그의 src가 완전히 로딩이 되고 난 후 imgSizeCheck 함수가 실행이 되어야만 하기 때문이다. 이미지 자체를 분석하여 사이즈를 찾는 것도 방법이 될 수 있겠지만 내 능력이 그렇게까지 되지 못하여 img태그의 src가 완전히 로드되고 그 이미지의 사이즈를 찾는 방식으로 진행을 한 것이다.
imgCheck가 실행되는 이유는 FaceDIv의 속성 때문이다. 자 다시 한번 FaceDiv를 보자.
"boundingBox" : {
"width":0.12929302,
"height":0.098517776,
"left":0.4796207,
"top":0.07781929
}
const [faceDivList, setFaceDivList] = useState<Array<JSX.Element>>()
const facesInfo = serverData.faceDetails.map(
(object: any, index: number) => {
const { left, height, top, width } = object.boundingBox
return (
<FaceDiv
key={index}
position="absolute"
left={`${left * 100}%`}
top={`${top * 100}%`}
width={`${width * 100}%`}
height={`${height * 100}%`}
/>
)
}
)
setFaceDivList(facesInfo)
const Parents = Styled.div`
position : relative;
`
const Child = Styled.div`
position : absolute;
background-color :rgba( 255, 255, 255, 0 );
`
<Parents>
<Child style={{ ...childViewStyle }}>{faceDivList}</Child>
<img ref={imgRef} src={imgAssets} onLoad={() => setLoad(() => false)} />
</Parents>JSON안의 값은 업로드한 이미지의 크기에 따른 비율인 것이다. 즉 FaceDiv의 부모 뷰인 Child 태그의 크기가 사용자가 선택한 이미지와 완전히 같은 크기가 되어야만 이 FaceDiv가 제대로 위치할 수 있는 것이다.
이렇게 하고 나면 아래 영상처럼 동작이 된다.
코드가 조금 양이 있는 만큼 글을 풀어나가는 방식이 어쩔 수 없이 스파게티가 되어버렸다.
이해하는데 어려움이 있을 것이 뻔하기에 프론트앤드(리액트) 코드는 깃허브에 올려놓았다.
오랜만에 즐기면서 코딩을 했다. 이런 식으로 HTML(JSX)을 사용해보긴 처음인데 괜찮게 한 것 같다.
그러나 문제가 없는 것은 아니다. 현재로선 이미지 사이즈를 동적으로 바꿔야 할 때 이 바운딩 박스의 위치와 크기를 이미지의 크기에 맞게 동적으로 바꿀 수 없고 눈이나 입의 위치를 알려주지는 않는다. 그저 얼굴이라는 것만 알려줄 뿐이다. 조만간 이러한 문제점들을 보완해야겠다.
https://github.com/vernonKwon/Rekognition_tistory/tree/main/front
vernonKwon/Rekognition_tistory
Contribute to vernonKwon/Rekognition_tistory development by creating an account on GitHub.
github.com
'개발' 카테고리의 다른 글
| Exception Safe Programming (0) | 2023.04.27 |
|---|---|
| AWS RDS MySQL 한글이 깨짐 오류(파라미터 그룹은 오류가 없을 때) (0) | 2021.02.08 |
| 리액트 리덕스 쉽게 이해하기 (0) | 2020.09.19 |
| Firebase Realtime database를 현업에 적용시켜보니... (2) | 2019.02.23 |
| 실무를 하고나서 뻘소리 (0) | 2018.11.18 |


